K-Meansクラスタリングの理解¶
目的¶
このチュートリアルを通してK-Meansクラスタリングの概念(どのように作用するか等)を理解してもらいます.
理論¶
よく使われる例を使って理論を理解しましょう.
Tシャツのサイズ問題¶
市場に対して新しいTシャツのモデルを売り出そうとしている会社を想像してください.あらゆるサイズの人々を満足させるために,その会社は様々なサイズのモデルを製作するでしょう.そこでその会社は人々の身長と体重のデータを作り,以下のようにグラフにプロットします:
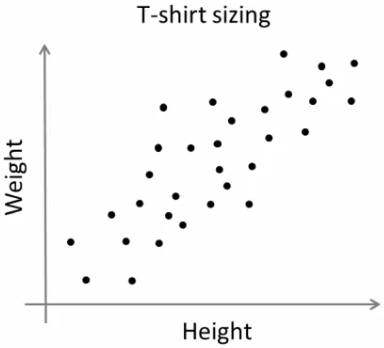
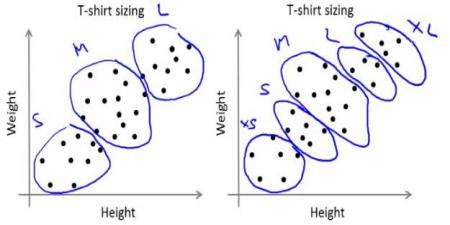
会社はあらゆるサイズのTシャツを作ることはできません.その代わりに,人間をSmall, Medium, Largeの三種類に分割し,全ての人にフィットするように3つのモデルだけを製作します.このグルーピングはk-meansクラスタリングによって行え,アルゴリズムによって全ての人を満足させるようなベストな3種類のサイズを決められます.そうでなければその会社はより多くのグループ(例えば5)に分割します.以下の画像をみてください:
どのように動作するのか?¶
このアルゴリズムは繰り返し処理になります.画像を使いながら少しずつ説明していきます.
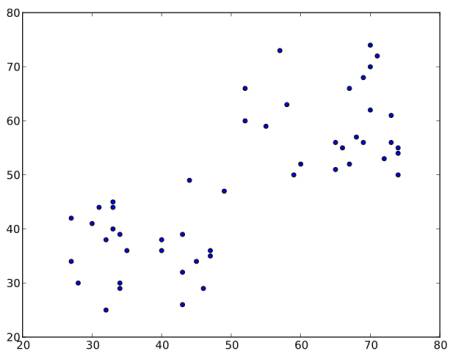
以下に示すようなデータを考えてください(上記のTシャツのサイズ問題のように考えてください).私たちはこのデータを二つのグループにクラスタリングする必要があります.
Step : 1 - アルゴリズムはランダムに2個の点 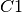 と
と 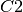 を生成し,重心とします(データ中の2点を重心としてランダムに選択することもあります).
を生成し,重心とします(データ中の2点を重心としてランダムに選択することもあります).
Step : 2 - 各点と両重心との距離を計算します.あるデータが に近ければ,そのデータを ‘0’ とラベル付けし, に近ければ ‘1’ とラベル付けします(重心の数が多ければ,ラベルは ‘2’,‘3’ とつけていきます).
上記の処理が終わった後に,‘0’ とラベル付けされた全てのデータに赤色, ‘1’ とラベル付けされた全てのデータに青色を塗ると,以下のような図になります.
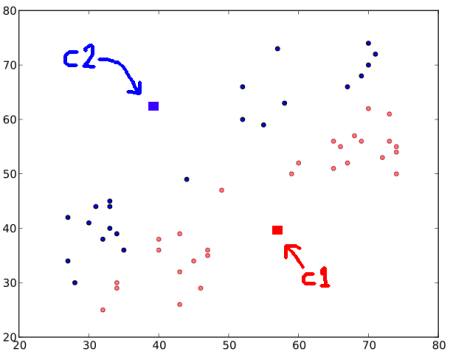
Step : 3 - 次に全赤点と青点の座標の平均値を計算し,新しい重心とします.これは と を新しく計算した重心へ移動させることを意味します(ここに載せている画像は正確なデータではなくあくまでもデモンストレーションである点に留意してください).
次は,新しく計算した重心を使って再びstep 2の計算を行い,全データに ‘0’ か ‘1’ のラベルを与えます.
その結果が以下の図になります:
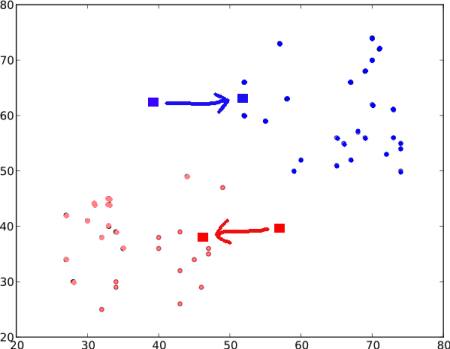
- 両重心が特定の点に収束するまで Step - 2 と Step - 3 を繰り返します*(もしくは,最大繰り返し回数や特定の精度を終了条件として繰り返し処理を停止させることもできます)*.
- これらの点はテストデータと対応する重心との距離の総和が最小となるような点となります.もしくは単純に
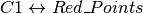 の距離と
の距離と 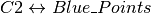 の距離の和が最小となります.
の距離の和が最小となります.
![minimize \;\bigg[J = \sum_{All\: Red_Points}distance(C1,Red\_Point) + \sum_{All\: Blue\_Points}distance(C2,Blue\_Point)\bigg]](../../../../_images/math/9b80d05ad90341c7c41b2a3da583f6c532465a9d.png)
最終的な結果は以下のようになります:
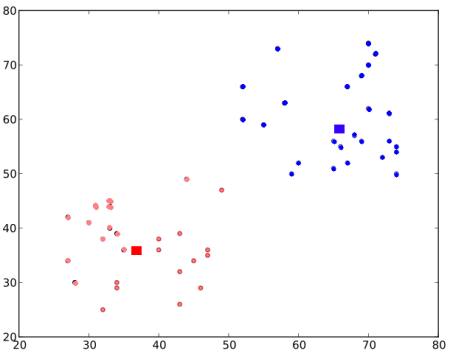
これがK-Meansクラスタリングの直観的な理解となります.更なる詳細な説明や数学的説明は一般的な機械学習の教科書や補足資料中のリンクを参照してください.それはK-Meansクラスタリングの最上層です.世の中にはこのアルゴリズムの改良版が大量にあります(重心の初期値の設定方法や繰り返し処理の高速化など).
補足資料¶
- Machine Learning Course, Video lectures by Prof. Andrew Ng (Some of the images are taken from this)