SIFT (Scale-Invariant Feature Transform)の導入¶
目的¶
- このチュートリアルでは
- SIFTアルゴリズムの概念を学びます.
- SIFT特徴点,特徴量記述子について学びます.
理論¶
前のチュートリアルではHarrisのコーナー検出器といったコーナー検出器について学びました.これらの検出器は回転不変(rotation-invariant)です.つまり,画像が回転したとしても同じコーナーを検出可能であることを意味します.画像が回転したとしてもコーナーがコーナーであることに変わりはないため,明らかと言えるでしょう.しかし,スケーリング(拡大・縮小)に対しても不変と言えるでしょうか?画像が拡大もしくは縮小されるとコーナーではなくなってしまうかもしれません.以下に示す画像を見てください.左側の小さい画像中のコーナーは右側の拡大された画像内ではコーナーではなくなっています.よって,Harris検出器はスケールに対して不変ではありません.
2004年にブリティッシュコロンビア大学の D.Lowe が発表した論文 Distinctive Image Features from Scale-Invariant Keypoints にて,Scale Invariant Feature Transform (SIFT)というキーポイントの検出とその特徴量の計算を行う新しいアルゴリズムを発表しました. (この論文は理解しやすくSIFTに関する資料で最も良い論文です.本チュートリアルの説明はこの論文の短い要約に過ぎません)
SIFTのアルゴリズムは4つの処理に大別されます.一つ一つの処理を見ていきましょう.
1. スケール空間における極値検出¶
上に示した画像から,異なるスケールにおいてキーポイントの検出を行うためには同じウィンドウサイズを使えません.小さいコーナーであれば問題ありませんが,大きなコーナーを検出するためには大きなサイズのウィンドウが必要になります.このために,スケールスペースにおけるフィルタリングを行います.具体的には,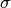 の値を変化させた Laplacian of Gaussian (LoG)を使います.ここで, がスケーリングパラメータの役割を担います.様々な値の:math:sigma のLoGを使うことで,ブロブ検出器として動作します.上記の画像を例にとると, の値が低いGaussianカーネルは小さいコーナーに対して高い値を出すのに対して, の値が高いGaussianカーネルは大きなコーナーに適しています.
位置とスケールに対して極大値を示す画素
の値を変化させた Laplacian of Gaussian (LoG)を使います.ここで, がスケーリングパラメータの役割を担います.様々な値の:math:sigma のLoGを使うことで,ブロブ検出器として動作します.上記の画像を例にとると, の値が低いGaussianカーネルは小さいコーナーに対して高い値を出すのに対して, の値が高いGaussianカーネルは大きなコーナーに適しています.
位置とスケールに対して極大値を示す画素 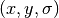 は,潜在的なキーポイントが位置(x,y),スケール にある事を意味します.
は,潜在的なキーポイントが位置(x,y),スケール にある事を意味します.
しかし,LoGフィルタは少々計算コストがかかるため,SIFTアルゴリズムではLoGの近似計算であるDifference of Gaussiansを使います.Difference of Gaussianは異なる2つの , 仮に と 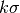 としましょう,によってボカシた画像の差分を取ることによって得られます.この過程はGaussianピラミッド中の異なるオクターブの画像に対して行われます.以下の画像に示します.
としましょう,によってボカシた画像の差分を取ることによって得られます.この過程はGaussianピラミッド中の異なるオクターブの画像に対して行われます.以下の画像に示します.
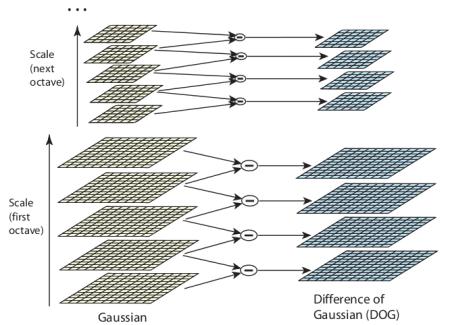
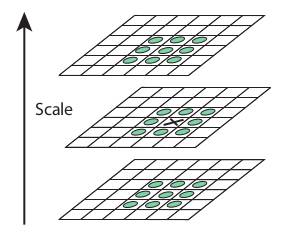
一度DoGを計算し,スケールと位置に対して極大値を探索します.具体的には,一画素に対して空間的な8近傍画素に加えて上下のスケール各9画素と比較し,その画素が極大値を示せば潜在的なキーポイントとなります.以下の画像で示すように,極大値を示すスケールはキーポイントが最もよく表されるスケールを意味します.
論文では経験的にオクターブ数を4,スケールの階調数を5,初期の の値を1.6,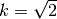 としています.
としています.
2. キーポイントの位置同定¶
潜在的なキーポイントの位置が見つかった後には,検出位置の精度を改善する必要があります.極値の検出位置精度を上げるためにはスケールスペースのテイラー展開が使われます.極値の値が閾値(論文では0.03)以下であればキーポイントの候補から除外します.この閾値はOpenCVでは contrastThreshold と呼んでいます.
DoGはエッジに対して強く反応するため,キーポイント候補に含まれているエッジも除外しなければなりません.これは,Harrisのコーナー検出器と似たような方法で実現します.2x2のHessian行列(H)を使って主曲率を計算します.Harrisのコーナー検出器のチュートリアルで既に学んだように,注目画素がエッジである場合,2つの固有値の差が大きくなります.そのため,論文では以下のような単純な関数を使っています.
この比が閾値(OpenCVでは edgeThreshold と呼んでいます)より大きければ,そのキーポイントは候補から除外されます.論文中では値が10に設定されています.
これらの処理によって,コントラストが低いキーポイントとエッジを取り除けるため,特徴の強いキーポイントが残ることになります.
3. 回転角の計算¶
次に回転不変性を実現するため,各キーポイントに対して回転角を計算します.スケールに依存してキーポイントの周囲の近傍領域を抽出し,抽出した領域に対して勾配の強度と方向を計算します.回転ヒストグラムは360度を覆うように36個のビンで定義されます.ヒストグラム中で最大となるピークと最大値の80%以上の値を持つピークを検出します.この回転角の計算によって同一の位置・スケールのキーポイントに対して異なる回転方向を割り当てます.このようにしてマッチングの安定性を実現します.
4. 特徴量の記述¶
特徴量記述子の話に移ります.キーポイントに対して周囲の16x16画素を取り出します.この領域を16個の4x4の小ブロックに分割します.各小ブロックに対してビンの数が8となるヒストグラムを作ります.結果として8個のビンのヒストグラムが16個,つまり合計で128ビンの数値がえられます.この128個の値を特徴量として保持します.更に,この128次元の特徴ベクトルに加えて,照明変化や回転に対する頑健性を実現するために様々な特徴量も保持します.
5. キーポイントのマッチング¶
2枚の画像間のキーポイントのマッチングは最近傍探索によって行います.しかし,特徴ベクトルが2番目に近いキーポイントが1番目に近いキーポイントに非常に似ているケースが生じることがあります.そのようなケースでは,両キーポイントの距離の比を計算します.比が0.8より大きければ2つのキーポイントが似ていることを意味するため,マッチングの候補から除外します.論文によると,この閾値処理によって約90%の誤対応を取り除きつつ,正しい対応関係は5%しか除外されません.
これがSIFTアルゴリズムの概要です.更に詳細を知りたい場合は原著論文を参照してください.一点注意しなければいけない点は,このアルゴリズムの特許が取得されている点です.そのためOpenCVではNon-freeモジュールの中に含まれています.
OpenCVにおけるSIFT¶
それではOpenCVで使用可能なSIFTの関数を見てみましょう.まずはキーポイント検出と検出したキーポイントの描画から始めます.まずはSIFTオブジェクトを構築します.SIFTオブジェクトに対して異なるパラメータを設定することが可能で,ドキュメントに詳しい説明が書いてあります.
import cv2
import numpy as np
img = cv2.imread('home.jpg')
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT()
kp = sift.detect(gray,None)
img=cv2.drawKeypoints(gray,kp)
cv2.imwrite('sift_keypoints.jpg',img)
sift.detect() 関数によって画像中のキーポイントを検出します.検出対象を画像中の小領域に限定したい場合はマスク画像を渡してください.各キーポイントは様々な属性((x,y)座標,スケール,回転角など)を持つ特別な構造体です.
OpenCVは検出したキーポイントの位置に小さな円を描く cv2.drawKeyPoints() 関数も用意しています. cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS というフラグを指定するとキーポイントのスケールに合わせたサイズの円を描くと共に回転角も示します.以下の例を見てください.
img=cv2.drawKeypoints(gray,kp,flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imwrite('sift_keypoints.jpg',img)
結果画像は以下のようになります.:

次に,特徴量を計算します.
- 既にキーポイントを検出しているため, sift.compute() 関数で特徴量を計算します.例:
kp,des = sift.compute(gray,kp) - キーポイント検出をしていない場合はキーポイント検出と特徴量の計算を sift.detectAndCompute() 関数を使って同時に行えます.
2つ目の方法を見てみましょう.
sift = cv2.SIFT()
kp, des = sift.detectAndCompute(gray,None)
ここでkpはキーポイントのリスト,desは 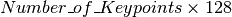 のshapeのnumpy.arrayになります..
のshapeのnumpy.arrayになります..
これでキーポイントと特徴量を得られたので,次に画像のマッチングを試しましょう.マッチングについては以降のチュートリアルに載せます.