背景差分¶
基礎¶
背景差分はComputer Visionを基にしたアプリケーションにおけるよく使われる前処理の内の一つです.例えば,固定カメラによる来客者数・退室者数の測定,屋外カメラを使った交通流計測などが挙げられます.このようなアプリケーションを実現するために,まず初めに画像中に写る人や車のみを検出する必要があります.技術的には,静的背景から移動物体を検出する問題を解かなければいけません.
背景のみが写った画像が手に入れば簡単な問題です.移動物体が写っている画像から背景画像を引き算すれば十分です.しかし,ほとんどの場合,そのような背景画像を取得できないため,どのような画像が手元にあるにせよ,背景を抽出する必要があるわけです.車の影が写ると更に問題は複雑になります.なぜなら影もまた移動するため,単純な引き算では影も前景物体とみなされてしまうからです.
このような目的のために,様々なアルゴリズムが紹介されてきました.OpenCVは簡単に使える3つのアルゴリズムを用意しています.一つ一つ紹介していきます.
BackgroundSubtractorMOG¶
これは混合正規分布(Gaussian Mixture)を基にした前景・背景の領域分割アルゴリズムで,P. KadewTraKuPongとR. Bowdenが2001年に発表した論文 “An improved adaptive background mixture model for real-time tracking with shadow detection” で提案されました.背景に属する各画素を混合数が3から5の混合分布でモデル化する手法です.混合分布の重みはシーン中に対応する色が存在している時間の割合を表しています.可能性の高い背景色は長く留まり,より静的になります.
実装する上で, cv2.createBackgroundSubtractorMOG() 関数を使って背景オブジェクトを作成します. 履歴の長さ,混合数,しきい値といったオプション指定するパラメータが幾つかありますが,それぞれデフォルト値は決まっています.背景オブジェクトを作成したら,それ以降は画像を撮影する度に backgroundsubtractor.apply() 関数を使って前景領域のマスクを取得します.
以下に示したシンプルな例を見てください:
import numpy as np
import cv2
cap = cv2.VideoCapture('vtest.avi')
fgbg = cv2.createBackgroundSubtractorMOG()
while(1):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
cv2.imshow('frame',fgmask)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
(この例も含めた全てのデモプログラムの結果は,このページの一番下にまとめて表示します)
BackgroundSubtractorMOG2¶
このアルゴリズムも混合正規分布を基にした前景・背景の領域分割アルゴリズムです.Z.Zivkovicが2004年に発表した論文 “Improved adaptive Gausian mixture model for background subtraction” と2006年に発表した “Efficient Adaptive Density Estimation per Image Pixel for the Task of Background Subtraction” を基にしています.このアルゴリズムの重要な点は,画素毎に最適な混合数を選択する点です(前の例ではアルゴリズムを通してK個の正規分布を使っていた点を思い出してください).照明の変化などといった動的なシーンに対する適応力が優れています.
前の例と同様,背景オブジェクトを作成します.ここでは影の検出を行うか否かを選択するオプションがあります.もしも detectShadows = True とすれば影を検出できますが,計算速度は遅くなってしまいます.デフォルトでは detectShadows = True となっています.影は灰色になります.
import numpy as np
import cv2
cap = cv2.VideoCapture('vtest.avi')
fgbg = cv2.createBackgroundSubtractorMOG2()
while(1):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
cv2.imshow('frame',fgmask)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
(Results given at the end)
BackgroundSubtractorGMG¶
このアルゴリズムは統計的な背景の推定法と画素単位でのベイス推定に基づく領域分割を組み合わせたアルゴリズムです.Andrew B. Godbehere, Akihiro Matsukawa, Ken Goldberg が2012年に発表した論文 “Visual Tracking of Human Visitors under Variable-Lighting Conditions for a Responsive Audio Art Installation” で提案されたアルゴリズムです.論文に記載されているように,サンフランシスコのContemporary Jewish Museumで2011年3月31日から7月31日の期間に “Are We There Yet?” というインタラクティブ オーディオ アートの展示で使われました.
背景のモデル構築に最初の数フレーム(デフォルトで120)を使います.ベイズ推定を使って前景物体である可能性を識別する確率的前景領域抽出アルゴリズムを使います.推定は適応的であり,照明変化に対する適応力を上げるために,古い画像より新しい画像を重視します.クロージングやオープニングといったモーフォロジカル処理を行いノイズを削除します.最初の数フレームの間は背景モデルを作成するため,真っ黒なウィンドウが表示されるでしょう.
ノイズを消すために,モーフォロジカル処理を適用すると良いでしょう.
import numpy as np
import cv2
cap = cv2.VideoCapture('vtest.avi')
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3))
fgbg = cv2.createBackgroundSubtractorGMG()
while(1):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)
cv2.imshow('frame',fgmask)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
結果¶
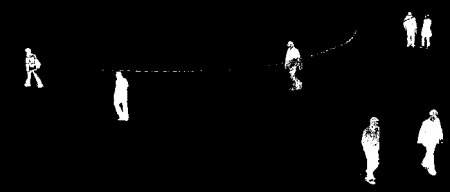
原画像
以下の画像は入力動画像中の200フレーム目の映像です.

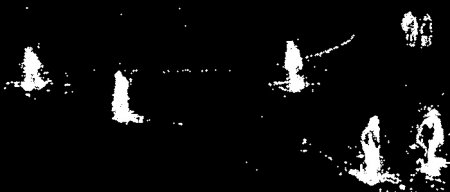
BackgroundSubtractorMOGの結果
BackgroundSubtractorMOG2の結果
灰色の領域は影領域を表しています.

BackgroundSubtractorGMGの結果
モーフォロジカル処理によってノイズが除去されています.