Haar Cascadesを使った顔検出¶
基礎¶
Haar特徴ベースのCascade型分類器を使った物体検出はPaul ViolaとMichael Jonesが2001年に”Rapid Object Detection using a Boosted Cascade of Simple Features”という論文で発表した効率過的物体検出手法です.この手法は機械学習を基にした手法で,大量の正例,負例の画像から分類器であるcascade関数を学習します.この分類器は学習が終わると,入力画像に対して適用されます.
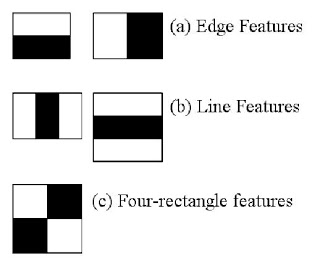
ここでは顔検出にこの手法を使います.最初にこのアルゴリズムは識別機の学習を行うために大量の正例(顔画像)と負例(顔が写っていない画像)を必要とします.これらの画像から何かしらの特徴を抽出する必要があるわけですが,以下の画像に示すようなHaar特徴量を使います.この特徴量はconvolutionで使うカーネルのようなものです.黒い四角形の領域に含まれる画素値の総和から白い四角形の領域に含まれる画素値の総和を引いた値がこの特徴量になります.
大量の特徴量を計算するために,各カーネルに対してあらゆるサイズ・位置を計算します(どのぐらいの計算が必要か想像してみてください.24x24のウィンドウでさえ160000個以上の特徴量になります).各特徴の計算に白・黒の領域に含まれる画素の総和の計算が必要です.この大量の計算を効率よく行うために,ViolaとJonesはintegral images(積分画像)を提案しました.画素値の総和計算を単純化し,どれだけ大量の画素の総和計算でもたった4画素を含む処理で計算できるようなアルゴリズムです.イケてませんか?処理をとてつもなく高速化できます.
計算される大量の特徴量の大半は,実は重要ではありません.以下に例を示します.上列の画像は良い特徴の一例です.最初の特徴は目の辺りの領域は鼻や頬の領域に比べて暗いという性質を捉えており,二番目の特徴は目は眉間より暗いという性質を捉えるようにHaar特徴カーネルが配置されています.しかしながら,頬の上やそれ以外の領域に全く同じカーネルを適用しても意味がありません.それでは,どうすれば160000個以上もある特徴から最適なものを選べるのでしょうか?この選択に Adaboost が使われます.

全学習画像上の全特徴に対して適用します.各特徴に対して,Adaboostは顔を顔とそれ以外のどちらかに分類するのに最適なしきい値を見つけます.当然ご識別やエラーが起きますが,正例と負例を最も良く分類するような特徴を選択します(この処理は説明ほど簡単ではありません.与えられた画像に対して最初は等しい重みを与えますが,識別を行う度にご識別が起きた画像に対する重みを増やして同じ処理を繰り返します.エラー率を再度計算し要求される精度に達するまで,もしくは既定数の特徴が見つかるまで重みの更新とエラー率計算を繰り返します.).
最終的な識別機はこれらの弱識別機の重み付き和になります.弱識別機に弱という言葉が付いている理由は,弱識別機単体では画像の識別ができないが,弱識別機を同時に使用することで強力な識別機になるからです.ViolaとJonesの論文では200個の特徴を使うだけでも95%の精度を実現できると書いてあります.最終的なセットアップでは約6000個の特徴を使用します(160000個以上の特徴に比べれば相当数を減らせたと言えるでしょう).
これで顔検出の準備が整いました.入力画像に対して24x24の小領域を定義し,6000個の特徴を適用し,顔か顔でないか確認します.この処理はちょっと非効率的で時間をくうと思いませんか?ViolaとJonesはこの処理のために良い方法を提案しています.
画像中の大半の領域は顔ではない領域です.ある小領域が顔ではないか確認する簡単な方法を使うと良いはずです.もしその小領域が顔でないのであれば,無視してしまい,二度と処理しません.その代わりに顔である可能性の有る領域に注力するのです.この方法で顔の領域である可能性がある領域の確認により時間をかけることができるようになります.
ViolaとJonesは,この処理のために Cascade of Classifiers(分類器/識別機の連結) の概念を導入しました.一つの小領域に対して全6000個の特徴の計算を行う代わりに,特徴を幾つかのグループに分け,グループ毎に順番に特徴の計算を行います(一般的には最初の数グループは少数の特徴を配置するようにしています).対象とする小領域が最初のグループで顔ではないと識別されれば,その小領域に対する処理はそれ以上行いません.最初のグループで顔であると識別されれば第二のグループの特徴を使って識別を行い,以降は第三,第四,…と処理を続けていきます.全グループによる識別で顔領域とみなされたものを顔が写っている領域であるとみなします.
彼らの論文では6000個以上の特徴を38個のグループに分け,最初の5グループの特徴数は1, 10, 25, 25, 50としています(上記の画像で示した二つの特徴はAdaboostから得られた最も良い二つの特徴です).著者らの論文によると,一つの小領域に対して,平均すると10個の特徴を計算することになるそうです.
これがViola-Jonesの顔検出のアルゴリズムの直観的な説明です.このアルゴリズムについて詳しく知りたければ,彼らの論文もしくは補足資料に挙げる資料を参照してください.
OpenCVのHaar-cascadeを使った顔検出¶
OpenCVは学習機と検出器の両方を提供しています.自分自身で識別機(例えば車検出や植物検出のための識別機)を学習したいのであれば,OpenCVを使った学習が可能です.詳しくは以下の資料を見てください: Cascade Classifier Training.
ここでは検出の部分を扱います.OpenCVはあらかじめいくつかの事前に学習を済ませた学習機を提供しており,例えば顔,目,笑顔検出のための検出器などです.これらは opencv/data/haarcascades/ フォルダ内に保存されているXMLファイルに保存されています.それではOpenCVを使って顔検出,目検出を行いましょう.
まず初めにXMLファイルから識別機を読み込み,次に入力画像(もしくは動画像)をグレースケールモードで読み込みます.
import numpy as np
import cv2
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
img = cv2.imread('sachin.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
次に入力画像に対して顔検出を行います.もし顔が検出されれば検出された顔の位置が Rect(x,y,w,h) として出力されます.これらの位置情報を取得すれば顔のROIを定義し,定義したROIに対して目の検出を行えます(なぜなら目は常に顔の中に位置するからです).
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
結果は以下のようになります:

補足資料¶
- Video Lecture on Face Detection and Tracking
- 顔検出に関する興味深いインタビュー Adam Harvey