k近傍法(k-Nearest Neighbor)の理解¶
目的¶
このチュートリアルではk近傍法(kNN)アルゴリズムの概念を理解します.
理論¶
k近傍法は教師あり学習のための分類アルゴリズムの中で最も単純なアルゴリズムの一つです.k近傍法のアイディアは特徴空間中でテストデータに最も似ているデータを探すという所です.以下の画像を使いながら説明していきます.
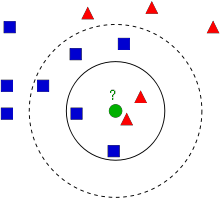
画像中には二つのグループが含まれています. 青い四角と赤い三角で区別されているグループです .各グループを クラス と呼びます. 両グループに所属しているメンバー(データ)は我々が 特徴空間 と呼ぶ地図上に分布しています (特徴空間は全てのデータが写像された空間と考えられます.例えば2次元座標空間を考えてください.各データはx, y座標と言う二つの特徴を持ちます.あたなはこの2次元座標空間中のこのデータを表現できますよね.三つの特徴があるとしたら3次元空間が必要になるわけです.では,N個の特徴があればどうなるかと言えば,N次元空間が必要になりますよね.このN次元空間こそがその特徴空間です.上記の画像では二つの特徴を持つ2次元空間の例だと考えられます) .
今,緑の円で表される新しいデータを取得したとします.このデータを青い四角か赤い三角のどちらかのグループに所属させる必要があります.この過程を 分類 と呼びます.具体的に何をすれば分類できるのでしょうか?k近傍法を使って分類をしてみましょう.
この新しいデータに最も近いデータを確認するという方法が挙げられます.画像を見ると,新しいデータに一番近いデータは赤い三角であることは明らかです.なので,個の新しいデータは赤い三角のグループに追加します.最も近い距離にあるデータにのみ依存する分類であるため,この方法は単純に 最近傍法(Nearest Neighbour) と呼ばれます.
しかし,この方法には問題があります.赤い三角のグループに属しているデータ最も近いものの,周囲のデータを見ると多くの青い四角のグループに属しているデータに囲まれているとしたらどうでしょうか?そのような状況であれば,赤い三角のグループより青い四角のグループに属している可能性が高いです.つまり,最も近いデータのみ確認するのでは不十分だということです.その代わりに近傍から k 個のデータを観ます.k個のデータの内が所属しているデータの数が多いグループは,どちらのグループに属しているデータが多かったとしても,新しいデータはそのグループに属することになります.例として上記の画像に対して k=3 と設定して分類をしてみましょう.新しいデータ(緑色の円)のk近傍点は赤が二つ,青が一つ(二つの青い四角が等距離に存在しますが,k=3と設定しているのでその内の一点のみ採用します).よって,このケースでも新しいデータは赤のグループに加えられることになります.では k=7 と設定したらどうなるでしょう?k近傍のデータは青いグループに属しているデータが5個,赤いグループに属しているデータが2個となります.そうです!!このデータは青のグループに加えられることになります.ここからkの値によって結果が変わるということが分かります.さらに面白いことに k = 4 としたらどうなるでしょうか?赤のグループも青野グループもそれぞれ2個ずつあり多数決ができません.つまり,kの値は奇数にすると良いということが分かります.kの値に依存する分類法であるため,この方法は k近傍法(k-Nearest Neighbour) と呼ばれます.
前述したようにk近傍法はk個の近傍点(データ)を考慮していますが,全てのデータを同等に扱っていますよね?これは正しいのでしょうか?例えば, k=4 のケースをもう一度考えてみましょう.結果は引き分けと言いましたが,赤のグループの方が緑のグループより新しいデータに近い位置にあります.この事実を考慮に入れると,新しいデータは赤のグループに加えた方が適しています.これをどうやって数学的に行えばいいのでしょうか?各データに対して,新しいデータとの距離に応じた重みを与えます.新しいデータに近い点に対しては大きな重みを,遠い点に対しては低い重みを与えます.それから各データに対して独立に与えた重みの和を計算します.どのデータに対して最大の重みが与えられようが,新しいデータはそのグループに所属するようになります.これを 変形k近傍法(modified kNN) と呼びます.
ここで重要な点は何でしょうか?
- 地図上の全データの情報をしる必要がありますよね?なぜなら近傍点を見つけるためには新しいデータと既存の全データとの距離を知る必要があるからです.もしデータとグループが大量に存在するのであれば,大量のメモリを消費し,計算時間も多くかかってしまいます.
- 学習や準備にかかる時間はほとんどありません.
それではOpenCVにおけるk近傍法をみていきましょう.
OpenCVにおけるk近傍法¶
上記の例と同様,ここでも二つのグループ(クラス)を使った簡単な例を使います.次のチュートリアルではより良い例を使います.
ここでは赤のグループを Class-0 (0と書きます),青のグループを Class-1 (1と書きます)として扱います.25個のデータを作成し,各データに対してClass-0かClass-1のどちらかのラベルを与えます.この作業はNumpyの乱数生成器を使います.
次にMatplotlibを使って生成したデータをプロットします.赤のグループは赤い三角形,青のグループは青の四角形としてプロットします.
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Feature set containing (x,y) values of 25 known/training data
trainData = np.random.randint(0,100,(25,2)).astype(np.float32)
# Labels each one either Red or Blue with numbers 0 and 1
responses = np.random.randint(0,2,(25,1)).astype(np.float32)
# Take Red families and plot them
red = trainData[responses.ravel()==0]
plt.scatter(red[:,0],red[:,1],80,'r','^')
# Take Blue families and plot them
blue = trainData[responses.ravel()==1]
plt.scatter(blue[:,0],blue[:,1],80,'b','s')
plt.show()
このチュートリアルで一番最初に見せた画像と同じようなプロットが表示されているはずです.乱数生成器を使っているため,コードを実行する度に異なるデータが得られます.
次にk近傍法のオブジェクトを初期化し, k近傍を学習するために trainData(学習データ) と responses(応答値) を与えます(検索木を構築します).
次に新しいデータを一つ作成し,OpenCVのk近傍法を使ってどちらのグループに属するデータか分類します.k近傍法を使う前に,テストデータ(新しく作成したデータ)について知っておく必要があります.データは,サイズが 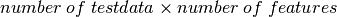 の浮動小数型の配列でなければいけません.次の処理は新しいデータのk近傍点の検索です.kのカウzを指定できます.k近傍法を使うと,返戻値として:
の浮動小数型の配列でなければいけません.次の処理は新しいデータのk近傍点の検索です.kのカウzを指定できます.k近傍法を使うと,返戻値として:
- k近傍法によって求めた新しいデータのラベル(クラス).最近傍法(Nearest Neighbour)を使いたい場合は k=1 と設定してください.
- k近傍点のラベル.
- 新しいデータとk近傍点との距離.
それではどのようにk近傍法が作用するか見てみましょう.新しい点は緑色の円として表示します.
newcomer = np.random.randint(0,100,(1,2)).astype(np.float32)
plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o')
knn = cv2.KNearest()
knn.train(trainData,responses)
ret, results, neighbours ,dist = knn.find_nearest(newcomer, 3)
print "result: ", results,"\n"
print "neighbours: ", neighbours,"\n"
print "distance: ", dist
plt.show()
以下のような結果を得ました:
result: [[ 1.]]
neighbours: [[ 1. 1. 1.]]
distance: [[ 53. 58. 61.]]
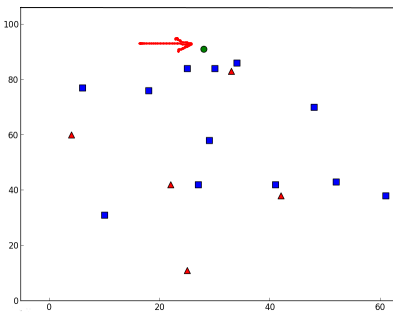
この結果によると,新しいデータは3個の近傍点をとり,全て青いグループに属しているデータです.よって新しいデータは青のグループのラベルを与えられました.以下のプロットを観れば明らかですよね:
大量のデータを持っている場合,k近傍法のオブジェクトに対して配列としてデータを渡せます.その場合,処理結果も配列として出力されます.
# 10 new comers
newcomers = np.random.randint(0,100,(10,2)).astype(np.float32)
ret, results,neighbours,dist = knn.find_nearest(newcomer, 3)
# The results also will contain 10 labels.