OpenCVのK-Meansクラスタリング¶
目的¶
- データクラスタリングのためのOpenCVの関数 cv2.kmeans() の使い方を学びます.
パラメータの理解¶
入力パラメータ¶
samples : np.float32 型のデータとして与えられ,各特徴ベクトルは一列に保存されていなければなりません.
nclusters(K) : 最終的に必要とされるクラスタの数.
- criteria : 繰り返し処理の終了条件です.この条件が満たされた時,アルゴリズムの繰り返し計算が終了します.実際は3個のパラメータのtuple
( type, max_iter, epsilon )として与えられます:
- 3.a - 終了条件のtype: 以下に示す3つのフラグを持っています:
- cv2.TERM_CRITERIA_EPS - 指定された精度(epsilon)に到達したら繰り返し計算を終了する. cv2.TERM_CRITERIA_MAX_ITER - 指定された繰り返し回数(max_iter)に到達したら繰り返し計算を終了する. cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER - 上記のどちらかの条件が満たされた時に繰り返し計算を終了する.
- 3.b - max_iter - 繰り返し計算の最大値を指定するための整数値.
- 3.c - epsilon - 要求される精度.
attempts : 異なる初期ラベリングを使ってアルゴリズムを実行する試行回数を表すフラグ.アルゴリズムは最良のコンパクトさをもたらすラベルを返します.このコンパクトさが出力として返されます.
flags : このフラグは重心の初期値を決める方法を指定します.普通は二つのフラグ cv2.KMEANS_PP_CENTERS と cv2.KMEANS_RANDOM_CENTERS が使われます.
出力パラメータ¶
- compactness : 各点と対応する重心の距離の二乗和.
- labels : 各要素に与えられたラベル(‘0’, ‘1’ …)のarray (前チュートリアルにおける ‘code’ ).
- centers : クラスタの重心のarray.
これから3個の例を使ってK-Meansアルゴリズムを適用する方法を示します.
1. 一つの特徴しか持たないデータ¶
一つの特徴歯科持たないデータの集合を考えます.例えば先ほどのTシャツ問題で身長のデータのみを使ってTシャツのサイズを決定する問題だと想像してください.
データの作成とMatplotlibによるプロットから始めましょう.
import numpy as np
import cv2
from matplotlib import pyplot as plt
x = np.random.randint(25,100,25)
y = np.random.randint(175,255,25)
z = np.hstack((x,y))
z = z.reshape((50,1))
z = np.float32(z)
plt.hist(z,256,[0,256]),plt.show()
このコードを実行して生成される ‘z’ はサイズが50,0から255の値をとります.’z’ を列ベクトルに変形したので,一つ以上の特徴がある時に便利になります.それからデータ型をnp.float32に変えました.
最終的に以下の画像が得られます:
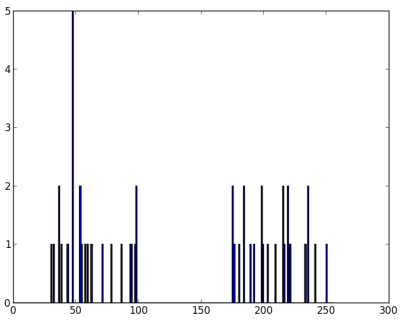
K-Means関数を適用する前に criteria を指定する必要があります.ここでは繰り返し回数の上限を10回とし,精度が epsilon = 1.0 に達した時に終了するように終了条件を設定します.
# Define criteria = ( type, max_iter = 10 , epsilon = 1.0 )
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# Set flags (Just to avoid line break in the code)
flags = cv2.KMEANS_RANDOM_CENTERS
# Apply KMeans
compactness,labels,centers = cv2.kmeans(z,2,None,criteria,10,flags)
このコードを実行するとコンパクトさ,ラベル,そして重心が得られます.今回は重心が60と207となりました.ラベルはテストデータと同じサイズとなり,各データには対応する重心データに依存して ‘0’,‘1’,‘2’, …とラベルが与えられます.それではラベルに応じて異なるクラスタに分割します.
A = z[labels==0]
B = z[labels==1]
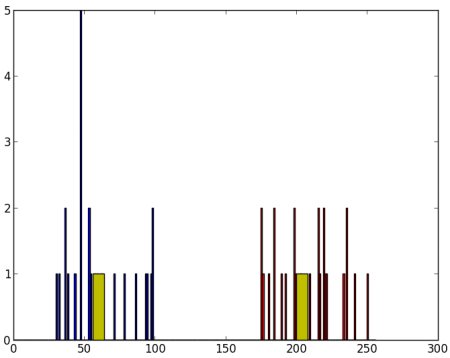
Aを赤,Bを青,各重心を黄色でプロットします.
# Now plot 'A' in red, 'B' in blue, 'centers' in yellow
plt.hist(A,256,[0,256],color = 'r')
plt.hist(B,256,[0,256],color = 'b')
plt.hist(centers,32,[0,256],color = 'y')
plt.show()
以下の図が出力として得られるプロットです:
2. 複数の特徴を持つデータ¶
前の例ではTシャツ問題で身長しか使いませんでした.ここでは身長と体重という二つの特徴を使います.
前の例ではデータを一つの列ベクトルとしていたことを覚えておいてください.各特徴は一つの列に配置される一方で,各行は一つの入力サンプルに対応しています.
例えば,今回の例では50人の身長・体重のデータを50x2のサイズのテストデータとして用意します.第一列は50人分の伸長,第二列は50人分の体重のデータに対応しています.第一行は二つの要素を持っており,最初の要素が一人目の身長,二番目の要素が一人目の体重を表します.同様に,残りの行はその他の人の身長と体重のデータを表します.以下の画像を確認してください:
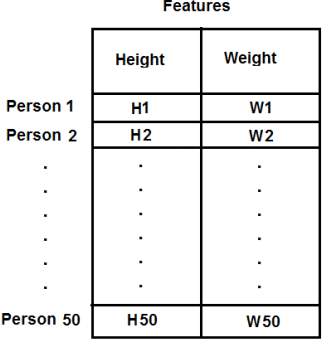
コードは以下のようになります:
import numpy as np
import cv2
from matplotlib import pyplot as plt
X = np.random.randint(25,50,(25,2))
Y = np.random.randint(60,85,(25,2))
Z = np.vstack((X,Y))
# convert to np.float32
Z = np.float32(Z)
# define criteria and apply kmeans()
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret,label,center=cv2.kmeans(Z,2,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS)
# Now separate the data, Note the flatten()
A = Z[label.ravel()==0]
B = Z[label.ravel()==1]
# Plot the data
plt.scatter(A[:,0],A[:,1])
plt.scatter(B[:,0],B[:,1],c = 'r')
plt.scatter(center[:,0],center[:,1],s = 80,c = 'y', marker = 's')
plt.xlabel('Height'),plt.ylabel('Weight')
plt.show()
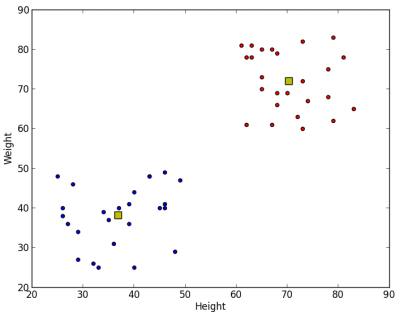
コードを実行した結果は以下のようになります:
3. 色の量子化¶
色の量子化は画像中で使用される色の数を削減する処理を指します.このような処理をする理由として目盛りの削減が挙げられます.制限された数の表示色しか表示できない装置があるかもしれません.このような状況で色の量子化が行われます.ここでは色の量子化にK-Meansクラスタリングを使います.
ここで新しく説明する事は何もありません.ここでは3つの特徴(色のRGB成分)があります.画像をMx3のサイズのアレイに変形します.ここでMは画像中の画素数を表します.クラスタリング後に重心の値(RGB値)を全画素に適用し,適用後の画像の色数が指定した数になるようにします.色変換後に原画像の形状に変形し直すことで出力画像を得ます.以下にコードを示します:
import numpy as np
import cv2
img = cv2.imread('home.jpg')
Z = img.reshape((-1,3))
# convert to np.float32
Z = np.float32(Z)
# define criteria, number of clusters(K) and apply kmeans()
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
K = 8
ret,label,center=cv2.kmeans(Z,K,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS)
# Now convert back into uint8, and make original image
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((img.shape))
cv2.imshow('res2',res2)
cv2.waitKey(0)
cv2.destroyAllWindows()
K=8 としたときの結果を以下に示します:
